

Imagine you have a digital document, in any format, and you want to make it available publicly. At the same time, you don’t want people to be able to change that document too easily. What do you do?
Here in Adevinta’s Edge team, we were asked that very same question by LeBonCoin, the #1 marketplace in France.
The Edge team oversees a media transformation service, called YAMS (Your Adevinta Media Service), that can transform images and documents, among other things, so we can say that we know a thing or two about digital documents.
So, our answer to LeBonCoin was: let’s convert every document into PDFs, but not just any PDF, we’re going to produce rasterized PDFs.
Hold on a second… What’s this rasterized PDF sorcery? Well, it’s just a regular PDF document, whose inner content is only images (even text, tables, lines, arrows and shapes are converted into pixels).
This offers a basic way to protect the document from modifications and it’s much more effective than adding a “change permissions password” to your PDF (which is super easy to circumvent).
In this article I will explain, with command line examples, what technologies and products we evaluated for the three steps involved in converting any document into a rasterized PDF.
Please note that we also considered commercial solutions, e.g. UniPDF, but I will only list open-source projects.
Why would you want to rasterize documents?
- If you want to add a watermark to your document, especially one that can’t be removed too easily.
- If you don’t want other people to mess with the document, especially with its text.
- If you want to make sure the document is displayed and/or printed identically regardless of the device, the OS, the reader application, the font set etc.
- If you want to make sure not to spread malicious code with your document.
Things you may need to know
Vector and raster
Digital images and documents can be roughly divided into two categories:
- Vector formats describe their content as “objects” and can contain text, shapes and other elements that can be moved around, modified, added and deleted.
Examples of vector formats are: PDF, SVG, DOCX, PPTX, etc. - Raster formats are collections of pixels (with a certain width, height and colour depth).
Examples of raster images are: JPEG, BMP, PNG, GIF, WEBP, etc.
The content of such image formats cannot be altered easily. For instance, it is harder to delete an object from a raster image than it is from a vectorial document.
Vectorial formats can also contain “image” objects. These are just raster images embedded in the vectorial format, but they remain raster images even if they are contained in a vector format, i.e. they don’t undergo a raster-to-vector conversion.
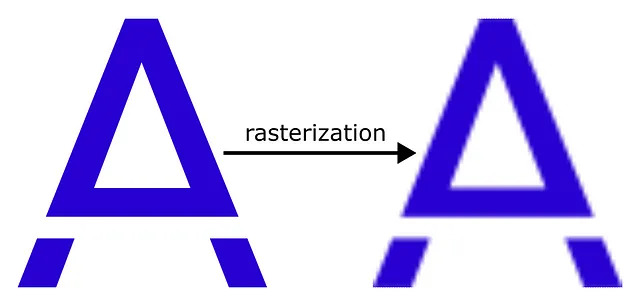
Rasterization
Rasterization is the process that takes a vector image and converts it to a raster image. Let’s explain it with an example:
Every time a Microsoft Word™ document is printed on paper, a rasterization conversion happens that transforms the shapes and text contained in the document into points that the printer can then transfer on paper.
It goes without saying that the process of rasterization is a lossy transformation. This means two things:
- There is loss of information when rasterizing a document, i.e. the rasterized image is like a static, flattened-out snapshot of the original document.
- The process is irreversible, i.e. it’s not possible to easily convert a rasterized image back into the original vectorial document. Emphasis on “easily”.
What does the rasterization conversion imply?
- The rasterized version file size is usually much larger than the original document.
- When displayed, the resulting rasterized image will not adapt easily to different zoom levels or screen resolutions. The same applies when printing.
- A rasterized document will lose all accessibility features, e.g. text-to-speech, alternative text description, navigational aids and audio description.
- The text that was present in the original document is converted into pixels and cannot be searched or copied.
- Hyperlinks in a raster image cannot be clicked, and their destination url is lost.
- Any audio and video content is lost.
- Editable forms, and all other advanced features, are lost.
What benefits does rasterization provide?
- Improved security (as the links and other advanced features, like scripts/macros, are lost in the conversion).
- Raster images are harder to tamper with, e.g. it’s more difficult to edit the text or to remove a watermark from a raster image.
- Improved portability, a raster image is shown identically regardless of the platform, the font set, the reader application, the OS etc.
Rasterizing a PDF
As with any vectorial format, PDFs can undergo a rasterization process.
This process takes a PDF file and, given a certain resolution, converts it to a set of raster pictures (usually one per page).
The resulting images contain all visible objects “flattened” on the same layer.
This is the equivalent of viewing a PDF file with a reader application and taking a screenshot of the displayed page.
Raster pictures in PDF
As described above, a vectorial format can contain raster images.
For example, you can add pictures to your Microsoft Word™ document, and they will be embedded as raster image objects within your vector format.
Logically, the same applies to PDF: it is a vector format, but it can accept embedded raster pictures.
This is usually the case when using a scanner to digitise a paper document and saving it as PDF. The resulting file is a vector format that embeds a raster image, usually one image per page.
Please note that rasterized PDFs are described in the ISO standard 23504–1:2020, whose main target are low-power devices. This means that your rasterized PDF, if done properly, has a higher chance of being displayed correctly on basically any device, as opposed to your input document.
PDF from a rasterized PDF
By using the two steps above, it is possible to convert an original vector document into a series of raster images and then create a new PDF that only contains these raster images (one per page).
Basically the final PDF file is a container for a set of raster images.
Tools
The following examples refer to the below open-source projects available for GNU/Linux as well as macOS. We haven’t tried with Windows as we exclusively use macOS and GNU/Linux as our development and runtime environments:
Step 1: Convert your document to PDF
First we take an input document, in virtually any format, and we convert it into a PDF.
Obviously, if your input document is already a PDF, you can skip this step.
If we assume that your input document’s name is “input.docx”, it can be converted to PDF using the following command (the new file will be created in the same directory in which the command is run).
LibreOffice
soffice --headless --convert-to pdf input.docxStep 2: From PDF to raster images
This is the step where the vectorial content of your PDF is converted into a bunch of pixels.
As we’re converting a vectorial object (described by a mathematical function) into a set of pixels, this process requires what’s called “a destination resolution”.
In other words, we’re taking an object that can be made as big or as small as you want (because it’s a vector) and we’re converting it into a static matrix of pixels. In order to do so, we must specify the resolution, i.e. the pixel density that the output raster image will have. This resolution is usually specified using the DPI (Dots Per Inch) unit, which represents the amount of pixels that can fit in a linear inch (or 2.54 cm). The higher the resolution, the higher the quality, but also the bigger the output object.
Common resolutions are:
- 96DPI (for viewing on digital screens)
- 150DPI (for low-resolution printing)
- 300DPI (for high-resolution printing)
ImageMagick’s and Poppler’s CLIs accept a destination resolution (150DPI in our examples), while LibreOffice’s one doesn’t.
We suggest experimenting with the different commands, supported formats and resolutions, in order to find the combination that works best for you.
Here’s a list of commands that will output raster images from your input PDF document (called “vectorial.pdf” in the examples below).
Please note: all the commands below will perform the same operation (converting a PDF into images), they are not meant to be executed one after the other. These examples show how to obtain the desired output with three different tools.
ImageMagick
convert -density 150 vectorial.pdf raster.pngLibreOffice + PDFtk-java
pdftk vectorial.pdf burst
for page in $(find . -name 'pg_*.pdf' | sort); do
soffice --headless --convert-to png ${page}
donePoppler
PNG:
pdftocairo -r 150 -png vectorial.pdf raster.pngJPEG:
pdftocairo -r 150 -jpeg -jpegopt quality=100,optimize=y vectorial.pdf raster.jpeg
TIFF:
pdftocairo -r 150 -tiff -tiffcompression lzw vectorial.pdf raster.tiff
Step 3: Build a PDF containing only raster images
Once we have a collection of raster images (one per page), we can build a new PDF that will only contain raster images.
For the sake of simplicity, the following commands assume that the raster images are in PNG format and their name follows the page[number].png pattern.
Please note: both the commands below will perform the same operation (wrapping several images into a single PDF file). They are not meant to be executed one after the other: they are examples of how to obtain the desired output with different tools.
ImageMagick
convert page*.png pdf-from-raster.pdfLibreOffice + PDFtk-java
soffice --headless --convert-to pdf page*.png
page_list=$(find . -name 'page*.pdf' | sort -n)
pdftk ${page_list} cat output pdf-from-raster.pdfConclusions
If you’re in the business of letting your users exchange digital documents, you may want to consider converting them to rasterized PDFs.
As digital documents are often used to spread computer viruses, Internet worms and all sorts of malicious code, converting a Microsoft Word™ document into a rasterized PDF is an amazing way to significantly reduce security risks. Moreover, it comes with the added benefits of (basic) anti-tamper protection and improved portability.
Rasterized PDFs do have drawbacks though, so you must decide whether these outweigh the benefits I have described.
With my team in Adevinta, we decided to deliver both vectorial and rasterized PDFs based on the use case at hand (it’s up to our users to decide). Currently our YAMS service handles ~26 billion requests per month, more than 10,000 per second. Of these, ~1.2 million are document transformation requests, ~14K of which are for rasterized PDFs.
I don’t know about you, but I call that a pretty successful feature.


