

When you’re on call, there are three kinds of pager notifications that make you sweat: DNS resolution errors, certificate expiration notices and network issues.
I work in a platform team that provides SCHIP, our internal runtime platform at Adevinta, which helps developers deploy and operate their applications. My team maintains the cluster and a myriad of services that support applications from observability to security passing through networking.
One evening, we received a page that some DaemonSets were failing. After logging on to the server and checking the pods status, our worst fear was confirmed as we read the error:
name=“aws-cni” failed (add): add cmd: failed to assign an IP address to container
Some context
When SCHIP (you can read more about it in these blogs: [1] [2] [3] ) started, we decided it should become a multitenant cluster. As a multitenant cluster, pods running in the cluster might need to contact AWS VPC resources deployed in other AWS accounts like an RDS database or an Elasticache. This means that we need to maintain some sort of ‘wiring’ between clusters and the VPCs used by internal customers.
When running an EKS cluster with the default VPC-CNI plugin, as recommended by AWS, the number of used IPs in the VPC will skyrocket as your cluster grows.
This is because VPC-CNI assigns one IP address to every pod. If your EKS cluster starts growing to, let’s say, 10000 pods, it will use 10000 IPs, which will need a sizable ipv4 address space block.
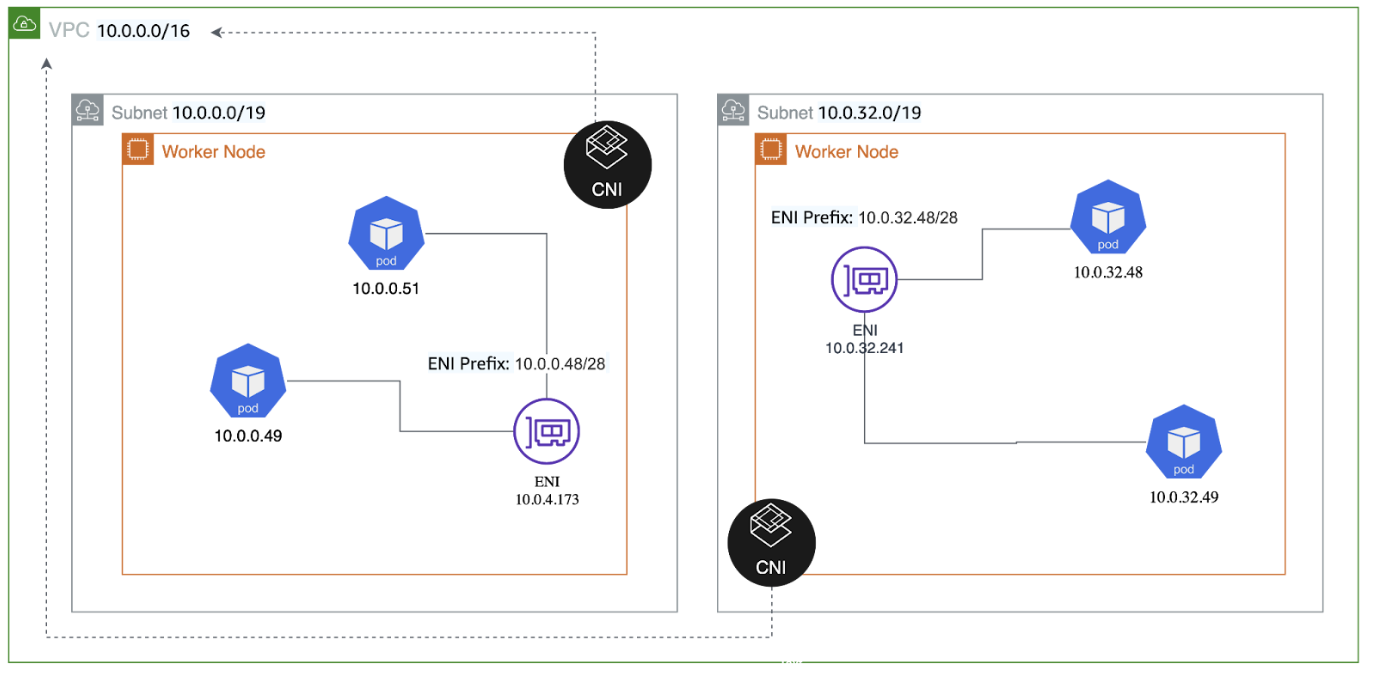
If you have a good forecast and capacity planning, you can manage this requirement. However, your cluster can get spikes in pods, like a job that goes rogue or a misconfiguration that launches several jobs that fail but keeps the IPs assigned until they are reclaimed.
A couple of years ago, we started our EKS journey in Adevinta. Soon enough, we discovered that IP address space could become an issue, and we began to monitor our usage.
Flash forward to the day of the fateful pager message at the beginning of this post. One of our clusters had issues due to failed pods. The network driver’s (CNI) error was very scary, with a clear message that ‘no IP address was available’.
Luckily, this issue affected only a relatively small and unused cluster. But now we were aware of this issue, the clock was ticking before we experienced a more severe, cluster-wide outage.
IP exhaustion using VPC-CNI in EKS is a known and public problem to which you have several solutions, including some suggested by AWS. The most comprehensive solution space description can be found in this article listing all the options.
That said, If you search for ‘VPC CNI ip exhaustion’ you will find several blog posts explaining the problem, the solutions and how to implement them (including this one, hopefully!)
What makes us unique?
If you are a cluster maintainer just creating the cluster involves taking several networking configuration decisions when using EKS on AWS:
- One or many CNI drivers that assign IP addresses to pods and potentially many other features like policies, observability and service mesh…
- A VPC layout, including
- Public and private subnets with dedicated address space
- An Internet Gateway for internet-facing traffic
- A NAT Gateway to allow instances deployed in the private subnet to reach the internet
- A protocol used (ipv4 or ipv6)
So long as everything you need is deployed inside the cluster, there are no additional networking needs.
But maybe at some point, the workloads you host in the cluster need to reach other parts of the private network. When this happens you need to figure out how to connect privately from the cluster to that outside VPC, since having network address overlaps makes connection harder.
The consequence is that you need to maintain an internal IPAM and a way to connect different VPCs. When we started we were simply using VPC peerings. But when those connections started to pile up we began using TGW to manage more connections between our clusters VPCs and tenants, and other VPCs from the organisation. This is important as it allowed us to solve the IP outage problem.
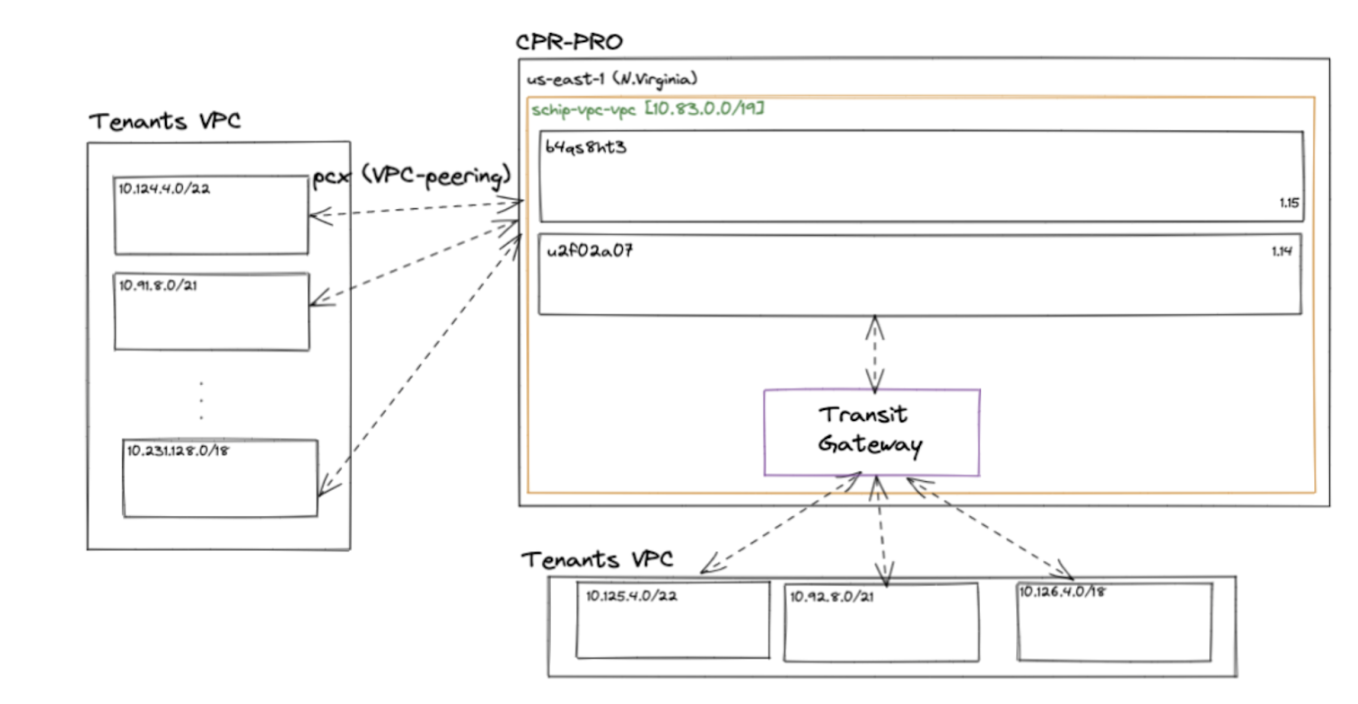
After we received the pager notification
The pager message landed in June in the middle of a massive migration to EKS-based clusters. Our distribution SCHIP was based in Kube-aws, and the runtime team was moving workloads to new clusters.
The message about not having enough IPs was worrisome but had little impact as the cluster affected was very small. But we started to think how we may be able to avoid this for the rest of the migration or when dealing with bigger clusters. We realised that something had to be done immediately – otherwise the next outage would be severe and unavoidable.
In our CPR team at Adevinta, we have dedicated time for experimentation. Every other Friday is reserved for exploring whatever technology or project catches the interest of any engineer in the team. Over the years we have experienced that such “apparent” waste of time has brought us incredible benefits, an example of which we have previously blogged about.
Fortunately, we had already dedicated some time to developing a solution for the IP exhaustion problem long before the frightening pager message. Some of our engineers spent several of their experimentation days to test:
- Avoiding the problem using another CNI driver like Cillium
- Using custom networking configuration in the VPC-CNI
- Testing IPv6 in the VPC-CNI in our environment
Avoiding the outage
After thorough testing in our context, it was easier to implement a custom networking configuration with a Secondary CIDR. This wasn’t the most elegant technical decision, but it allowed us to finish the migration on time.
Moving to another CNI like Cilium would have solved the problem, but it introduced some new challenges and unknowns that would need to be resolved.
Configuring VPC-CNI to use IPv6 would have added less unknowns and challenges, but there would still be some requiring time and resources to address.
In late August, we started a controlled rollout of custom networking in our smaller clusters with promising results. In September, we needed to pause the migration as the number of available IPs was very low.
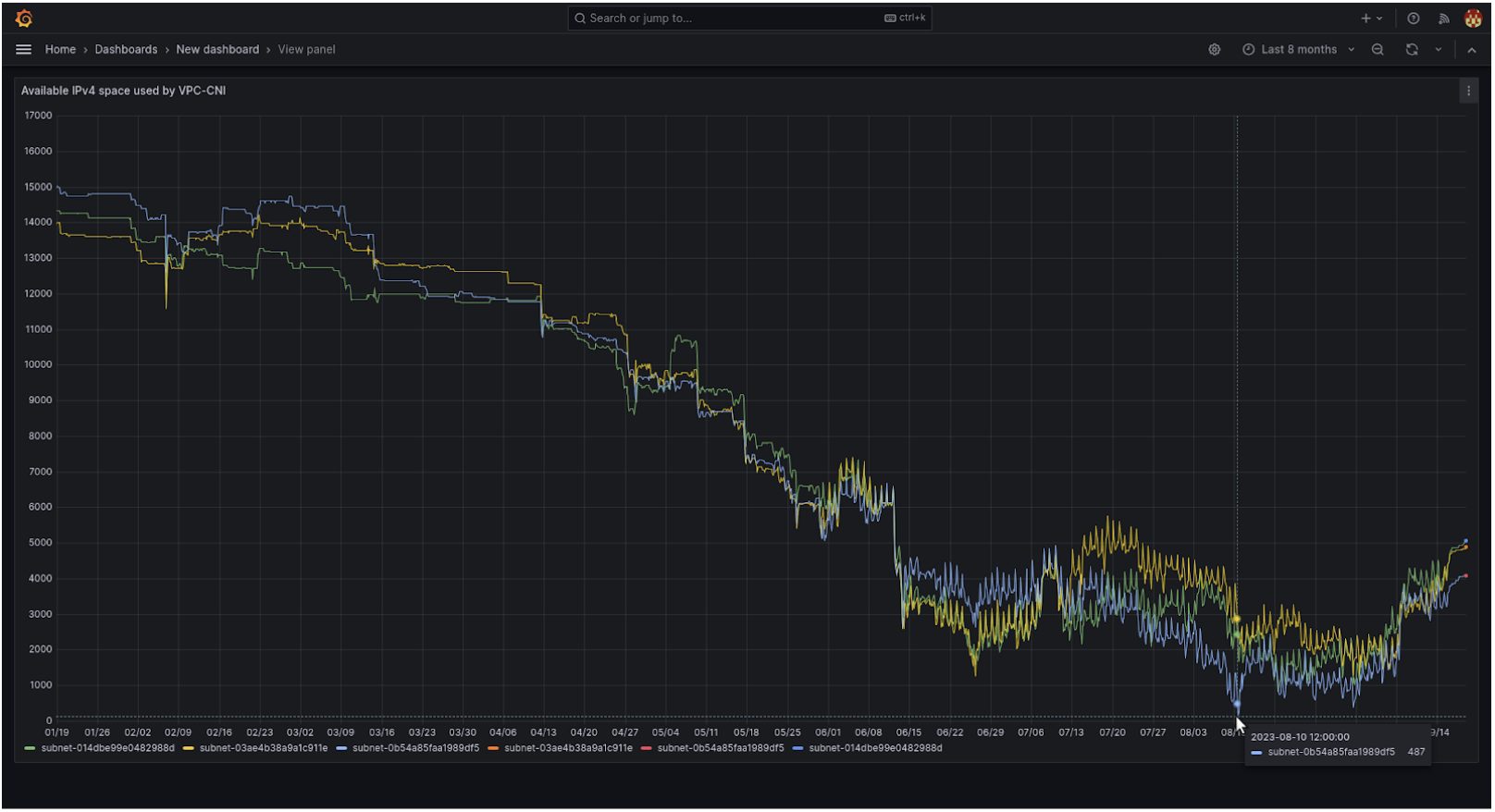
Since the controlled rollout was a success we continued rolling out custom networking with the rest of the fleet.

That allowed us to continue and finish the migration to EKS and avoid a huge outage that would have adversely affected most of our clients and marketplaces.
Extra ball: Karpenter
Some months later we started the migration to Karpenter. As Michael Ende says ‘But that is another story and shall be told another time’ but that migration project reminded us of this limited IP address issue.
Karpenter might, and probably will, provision smaller instances. This is because the number of ENIs and IPs depends on the instance size. This meant we started receiving pager alerts about a lack of IP addresses again.
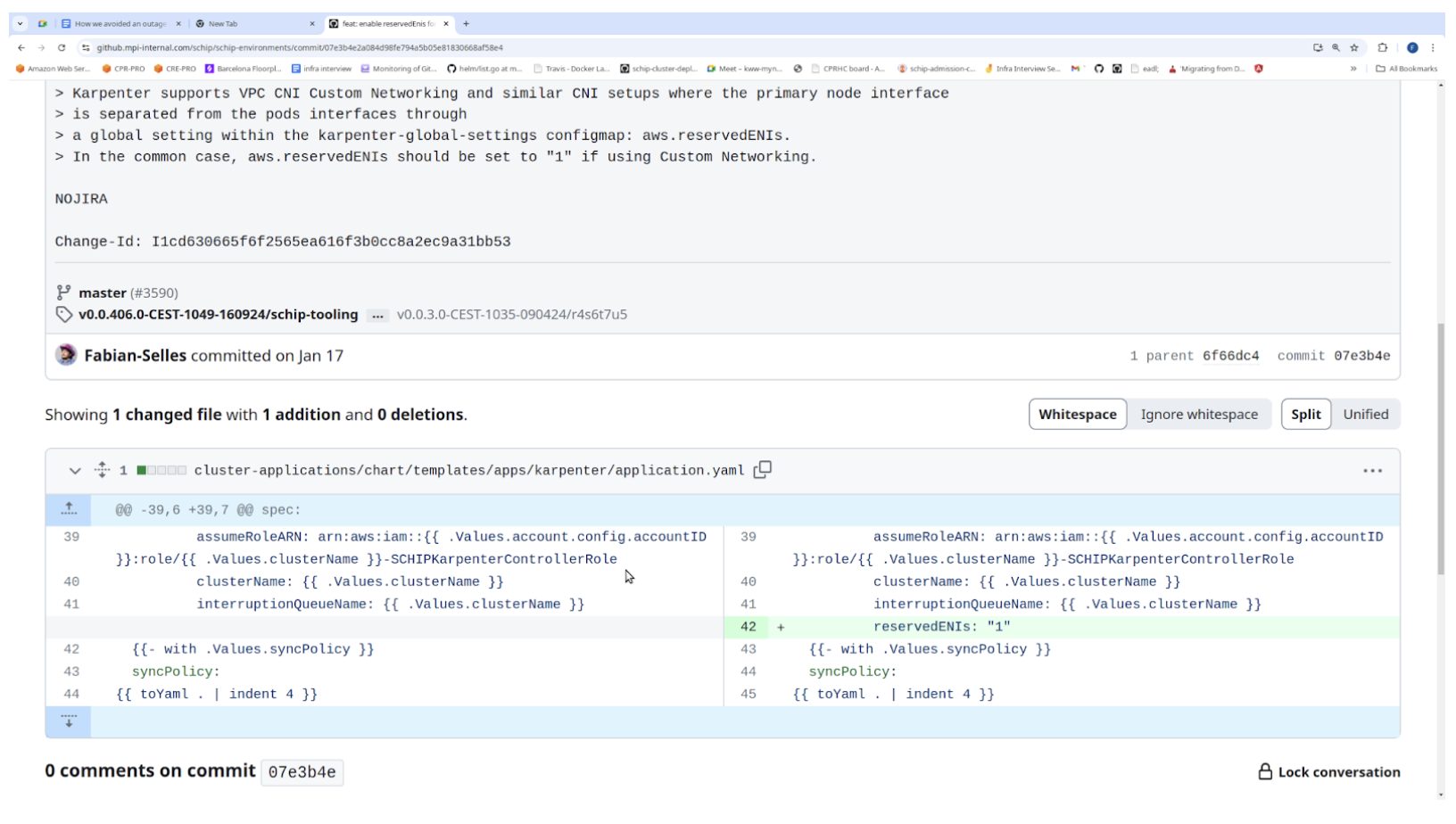
The main problem is that Karpenter was not aware that we were using Secondary CIDR and custom networking. In the Karpenter deployment, we needed to add the –reserved-enis parameter. This setting allows Karpenter to compute the number of pods that fit a node, taking into account that the first ENI would be used for the custom networking.
Final words
As a platform team or a cluster maintainer vpc-cni is not ready to scale and be used in production unless you spend some time thinking on capacity planning, every option has its pros and cons. If you are starting to deploy large clusters today it’s worth checking if you can use IPv6 which is the cheaper and more future-proof option. In any case don’t assume that if it works in small clusters it will work when scaling up.


