

It has been almost three years since I published my first blog about the collaborative process of building a Machine Learning platform. At the time, I had been with Adevinta for less than a year and there were still many concepts I was trying to master. Similarly, the Machine Learning Platform was more of a set of scattered tooling rather than an integrated workspace, and we were struggling to provide our users with a clear and easy-to-follow way of doing Machine Learning.
Fast-forward 18 months to January 2023. The ML Platform adoption had grown considerably and was expected to keep growing throughout the next quarters. At the same time, our tooling had been extensively used by several teams across the company and some pain points had been identified.
In some cases, teams had developed their own tooling to address these pain points, which had led to an heterogeneous ML community which was difficult to support. Moreover, we started to see how this heterogeneous growth diverged from our platform’s engineering principles, which posed a risk to us and our users.
We decided that was a good moment to take a break, do a bit of retrospective, gather feedback on the development experience we were offering our users, and iterate our tooling based on it. We had to pay special attention to the different user personas that were actively using our platform, which now ranged from ML Engineers to Data Scientists, Data Analysts or even Business Intelligence profiles. We wanted to involve all these people in the process as much as possible, to validate each iteration of what was going to be the tooling they would use every day (if we did it right).

This article intends to explain the Machine Learning Golden path that resulted from this collaborative effort, which involved many great professionals from our international family of colleagues.
The starting point
Adevinta’s ML Platform is built on top of an ecosystem of Kubernetes clusters, and can be understood as a layer of Machine Learning services that are available from within the clusters. The most relevant of these ML services are Kubeflow Pipelines, a platform for building and running Machine Learning workflows; and MLflow, which we use as a Model Registry, (you can learn more about the platform itself in the first article I wrote). We supplied our users with a template that simplified the creation of new ML projects, making it easy to start operating in the platform. Or at least this was our intention.
The feedback we received on our tooling was clear. The coupling between the Machine Learning code and the engineering & infrastructure related code made our tooling — especially the template — too complex to use. Many users were struggling to understand all the concepts and technologies that were present in the template, which filled their workspace with black boxes that they couldn’t debug on their own.
There were also some design limitations in the template that we were already aware of. The template was designed to allow a single Kubeflow Pipeline in the project, and a single container shared by all the pipeline steps defined in that project. This was a common way of working in Adevinta Spain, from which we drew inspiration when we created the template. However, this design decision already clashed with the ways of working of other marketplaces, such as Leboncoin (France) or Marktplaats (Netherlands), which had multi-pipeline and multi-container projects.
Taking all these factors into account we went through some very thorough discussions. One of these discussions took 16 hours over the course of 3 days. It was as intense as insightful, and we finally agreed on an initial design proposal for Adevinta’s Machine Learning Golden Path.
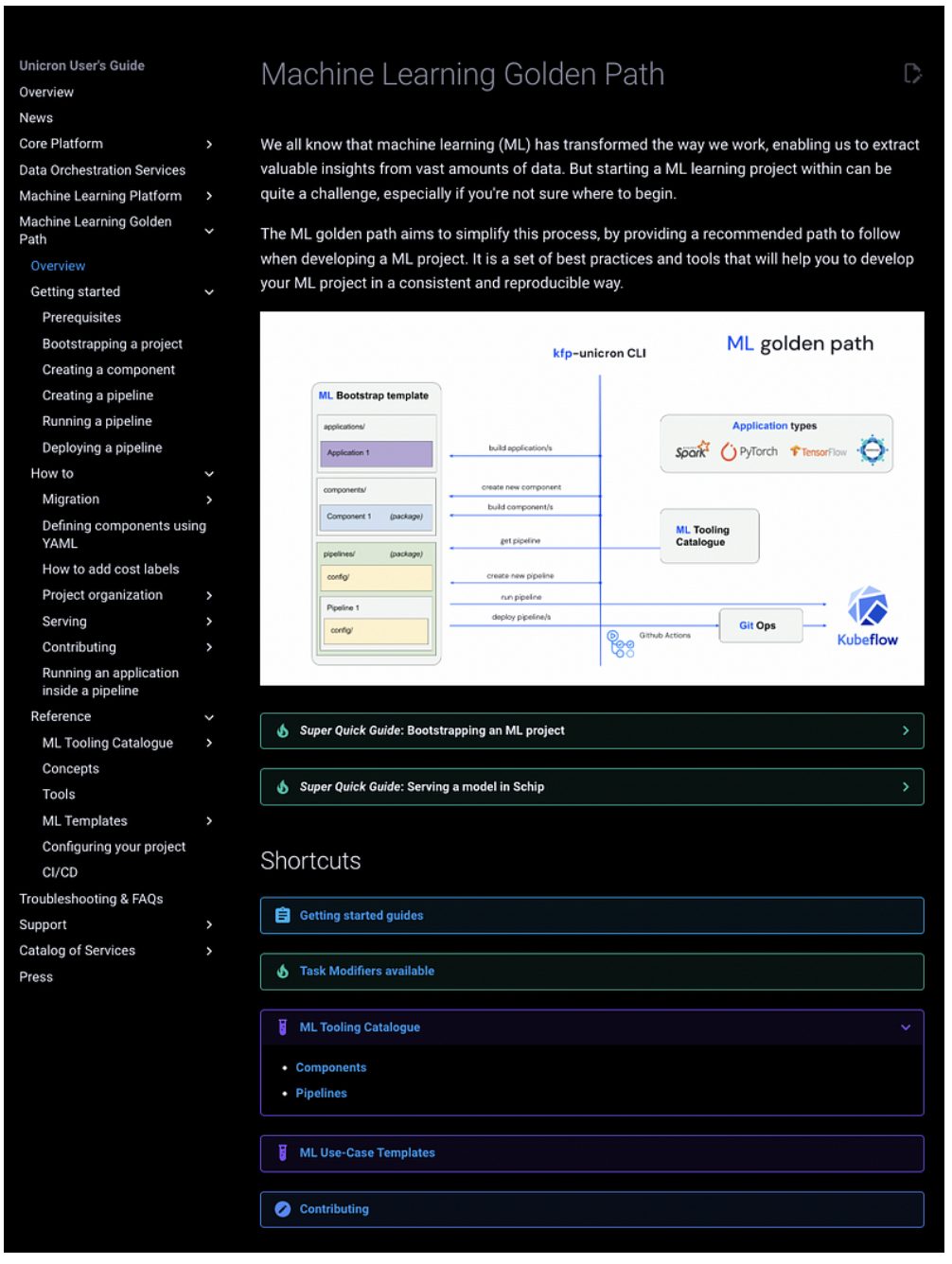
The proposed solution
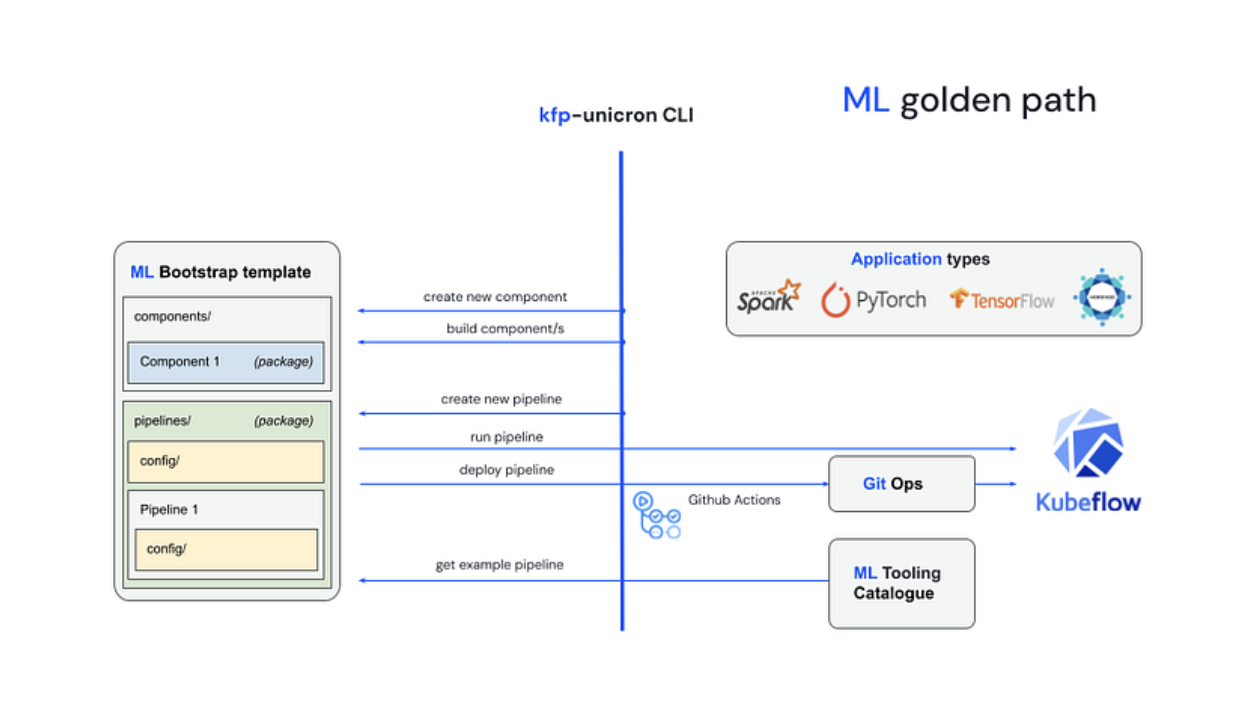
The schema above is simple and somewhat reductionist, as it hides many of the complexities of the ML development process. But it gives an initial idea of all the pieces involved, while allowing a quick look at the whole picture. These pieces could be organised in two semantic layers: the Core Layer and the Outer Layer.
Core Layer
The core layer contains the two main blocks of the ML Golden Path, which you can see on the left side and centre of the schema:
- ML Bootstrap Template: A template for bootstrapping Machine Learning projects, which can be accessed from either the command line (Copier) or through a UI (Backstage).
- KFP-Unicron: A powerful CLI to interact with any step of the Machine Learning end-to-end lifecycle, from linting and testing the ML code, to running and deploying Kubeflow Pipelines.
ML Bootstrap Template
The template follows an opinionated structure which was considered state of the art at the time. We evaluated our former template as well as Leboncoin’s — the existing solutions in the company — and also a sample project provided by Google Cloud Platform on how to organise Vertex AI projects, based on Kubeflow Pipelines.
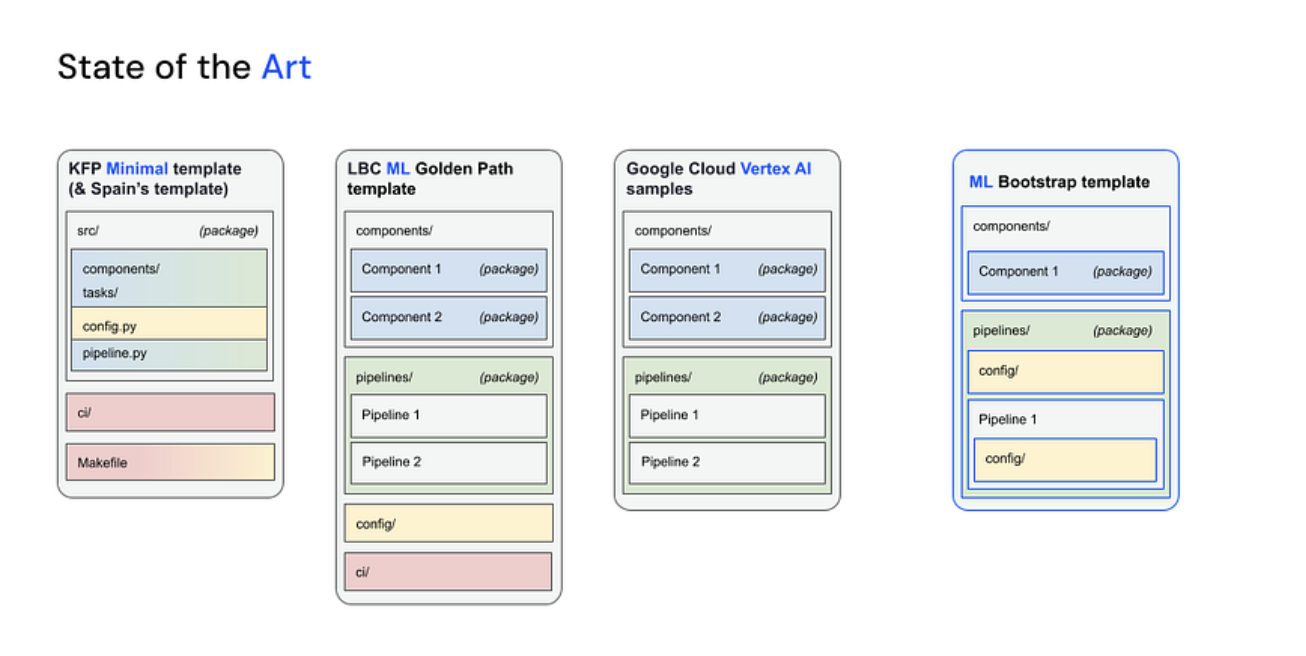
At first glance, it is easy to understand the coupling mentioned in our users’ feedback. In the former template — KFP Minimal Template, on the left of the diagram above, there’s a single Python package that contains both the components or ML business logic modules (in blue) and the pipeline and its configuration (in green and yellow, respectively), which is more engineering related. There is also some coupling between the infrastructure related code (in red) and the pipeline configuration (in yellow), which makes it difficult to understand which is which. Clearly, the project structure was already limiting the ML developer to a single pipeline and a single container per project, in a coding workspace that was messy and confusing.
On the other hand, Leboncoin and Google templates made a real distinction between the components — which now were organised in multiple, isolated containers — and the pipelines package, which could be understood as an orchestration module. From our perspective the pipelines package should not contain any business logic dependencies. Instead, it should only know how to interact with Kubeflow Pipelines within the context of the ML Platform.
So, we decided that the new template — highlighted in blue on the right of the diagram— would follow the same project structure as Leboncoin’s and Google’s templates. We also iterated on Leboncoin’s configuration strategy, which lived isolated in the root of the project and was difficult to relate to the pipeline’s code. So, with some re-organising here and there and a bit of cleaning, we managed to:
- Decouple the ML related logic (Data Science) from the orchestration related code and its configuration (ML Engineering).
- Allow for multi-container and multi-pipeline projects, addressing the main limitations of our existing solution.
- Expose the pipeline modules making them easier to read, and to access the configuration relevant to the pipeline and its execution (i.e. pipeline run definitions, resources management etc).
- Add a two-level configuration layout that allows for information reusability across pipelines (i.e. cluster-specific information, data roles etc).
- Let users organise their projects with flexibility: from maintaining the former single-pipeline — single-container structure to a complete mono-repo approach, including projects organised by ML use-cases or even technologies (i.e. Computer Vision repo, Pytorch models repo etc).
- Move all code related to continuous integration and infrastructure (in red) away from the ML developer’s workspace (explained in more detail below).
KFP-Unicron
As mentioned before, there was a lot of code in the ML developer’s workspace that was related to the project’s continuous integration flow. This was very infrastructure focused and far from the scope and knowledge of the majority of ML developers. To reduce their cognitive load while at the same time giving them more autonomy, we opted for hiding all this code behind a powerful and flexible CLI.
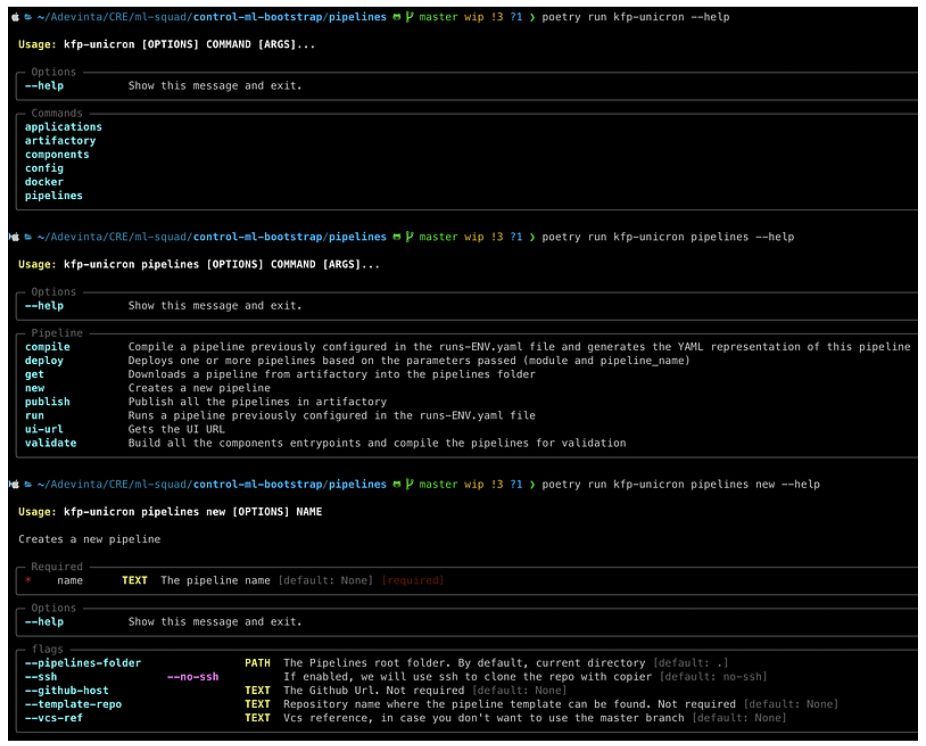
This CLI comes installed in our users’ projects by default (through our templating strategy). It allows them to do everything that they were able to do until now and more, but in a more controlled and guided way. Thanks to Typer, we have been able to provide our users with a very powerful and interactive CLI that is easy to use and discover. Below are some examples of the kind of help messages that the CLI provides.
Outer Layer
Up to this point, the Core Layer of the ML Golden Path was intended to cover everything that was offered by our previous solution but in a clearer, more flexible way. For instance, the image below shows the steps a user must complete to create a new project from our new ML Bootstrap Template, and to run a basic Kubeflow pipeline from their new project. Completing these steps will guarantee everything works as expected.
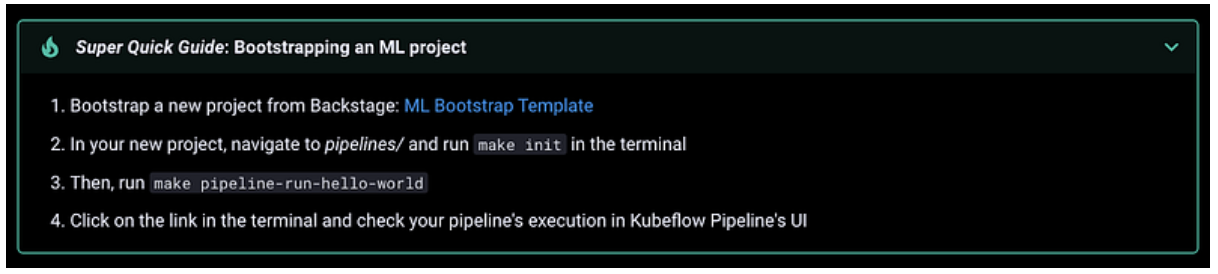
However, we purposely left one piece of old tooling out of the new ML Bootstrap template.
The previous template —KFP Minimal Template — contained an embedded example pipeline, together with its corresponding example business logic. It was aimed at letting the user quickly deploy a test model with a simple API, to familiarise themselves with the ML end-to-end lifecycle. But the whole point of using Copier for the templating was its update flow, which allowed users to update projects from the base template at any point, letting them bring new features into their ML projects.
This embedded example pipeline contained so much business logic and engineering code that it made the Copier updates immensely complex, turning them into another black box for our users. This is why we decided to move this kind of tooling to the Outer Layer.
The Outer Layer is nothing but a set of use-case specific tooling that is built on top of the Core Layer. This includes:
- Templates based on the ML Bootstrap template for complex use-cases, such as running Spark jobs or doing Distributed Training with Pytorch or Tensorflow (applications in the ML Golden Path schema above).
- Kubeflow Pipelines for common use-cases — such as registering models in MLflow or serving models in production — which can be downloaded as a raw folder using the KFP-Unicron CLI, and executed as they are or customised and expanded from the user’s workspace.
- Reusable Kubeflow Components used in the two cases above, can be used to create more reusable tooling (together with the pipelines, they comprise the ML Tooling Catalogue seen in the ML Golden Path schema above).
This is the actual beauty of our new ML Golden Path. We designed a simple, modular and homogeneous ML Golden Path that can be expanded with flexibility. The Golden Path enables our users to be fully autonomous through a progressive learning curve and a continuously expanding ecosystem of ML tooling.
Of course, all this tooling is supported by extensive and comprehensive documentation, which we organised following the Diátaxis framework. Diátaxis gives a clear and homogeneous structure to our documentation, which is aligned with our ML Golden Path. I actually love how they define it in their website:
Diátaxis is a way of thinking about and doing documentation.
What we want to provide is a way of thinking about and doing Machine Learning in Adevinta.
Building a healthy ML development community
With ML Golden Path, we intend to power up Adevinta’s ML development community through an ecosystem of homogeneous and reusable tooling that they can understand and expand. This is why it was so important for us to define a basic common ground — the Core Layer — which should be easily understood by everybody (that is, we have to make it easy to use and understand). Only then can we guarantee a healthy and self-sustaining ML community that can support each other and grow together.
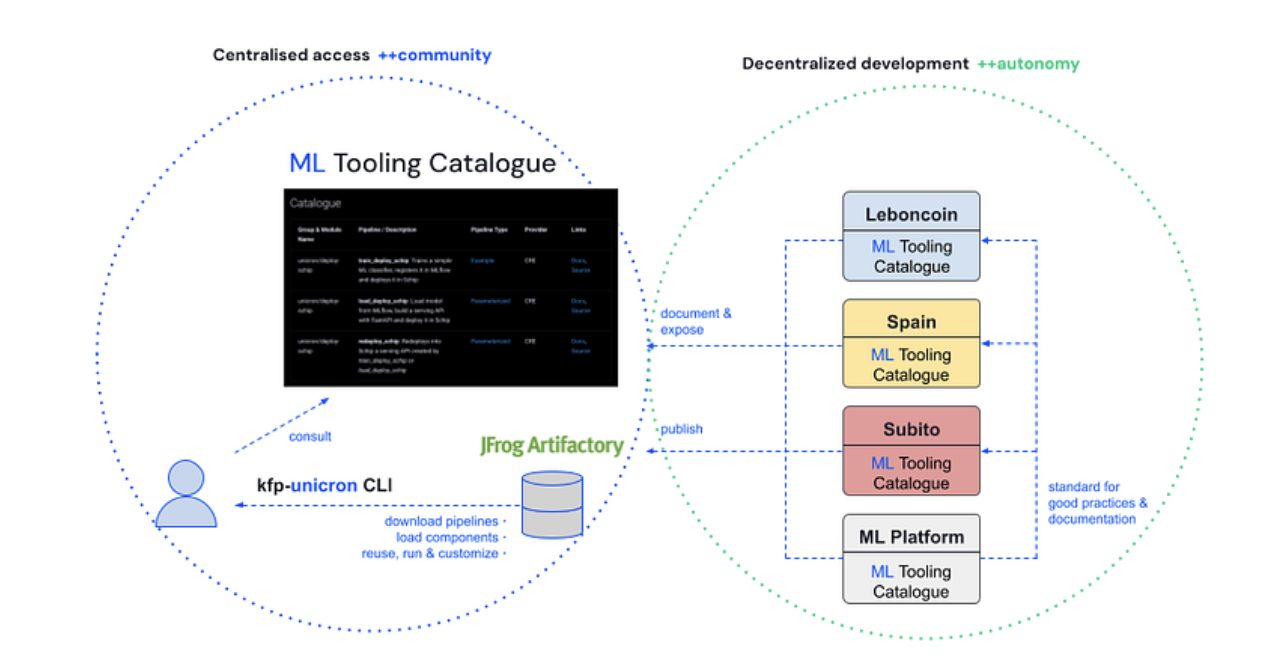
The schema above shows how we envision the ML Golden Path shaping Adevinta’s Machine Learning community. We provide our users with a central access point to all ML related tooling (left side of the diagram), that helps newcomers familiarise themselves with the complex ML ecosystem of the company. At the same time, the tooling we provide is hosted in our ML Tooling Catalogue repo (bottom right of the diagram), which is created from the ML Bootstrap template as any other ML project. This provides our users with a good example of what an ML Golden Path project looks like.
Not only that, but we also encourage our users to create their own team-specific ML Tooling Catalogues, giving them the autonomy to develop and release their own tooling (right side of the diagram). And if there’s any tooling in these catalogues that we think could be exploited by other teams, we can promote it to the central access point (left side of the diagram), effectively closing the circle.
A personal note
I have to admit that I have enjoyed working on this project very much, which you have probably guessed from the length of this story. 😅
First of all, I appreciate immensely the trust my manager placed in me to lead this effort as my Master’s final thesis. He provided incredible support and guidance throughout the whole process, to make sure we found the proper solution to the problem at hand. I’m also very fortunate to have an amazing team of experts around me, that has been fully invested in the project since day one and contributed with their knowledge. Finally, I really want to thank everybody involved from Subito in Italy, who were early adopters of this project and have been firm supporters since. Without them, this project would not have been possible.
When I first started thinking about the proof of concept of this project, I had an image very present in my mind: the scene from Toy Story 2 in which Woody gets fixed by an expert repairman. The scene is incredibly satisfying, and it is probably my favourite from Toy Story. But beyond the satisfaction of the repair work, I have to admit that I love how the repairman’s box becomes a perfectly tailored workspace for fixing and making toys ready. This was precisely the feeling I wanted to bring into our project, replacing Woody with Machine Learning models of course. In fact, I originally called it ML Studio until a colleague mentioned the name was already taken (a true pity).

I also had in mind some sort of motto for this workspace, which I ended up using later in several of the workshops we ran in our offices around Europe:
Use it quickly first, learn it progressively later
A simple sentence which contains a lot of meaning, since it implies an easy onboarding, a well-guided learning curve and the ambition and will of understanding your workspace.
I personally think the adoption and the results of the workshops were very satisfactory. We managed to help both Data Scientists and ML Engineers better understand parts of the ML ecosystem that always existed, but were less accessible.
We were very focused on not hiding any of the external technologies — Kubeflow Pipelines or MLflow — behind our custom wrapper syntax. Rather, we wanted to integrate them seamlessly with our syntax, creating parallel and independent learning modules. Thanks to our new ML Golden Path we helped our users understand Kubeflow Pipelines better, which is probably more important than understanding how the whole ML Golden Path works.
Finally, I’d like to share that I am an enthusiast of learning, about anything to be honest, especially if the person you are learning it from is passionate. I like to understand what I’m doing and how my tools and environment work, which is probably why I enjoy consuming (and hopefully writing) good documentation.
Being a programmer of any kind implies a heavy load of challenges that arise not from the problem at hand but from the attempt at creating a suitable workspace. I hope we have managed to create a workspace that is fun to learn and use, at your own pace and with the support and guidance of a healthy development community.


