

TLDR;
Some applications need to read data from heterogeneous Kafka topic formats to perform data transformations or data validation. Each of these topics can encode data in one of a number of supported formats. To reduce the need for dedicated configuration and to be resilient in the face of external errors, JSON and AVRO data deserialization can be achieved with “automatic data format detection” based on the first bytes of each message.
Introduction
At Adevinta, we receive almost a billion UBCT (User/Behavioural/Content/Transaction) events a day from marketplaces and Global Teams in Yotta’s Data Platform and this number is growing with every marketplace integration. Our team helps other teams to FMDQ (filter, map, dispatch and measure data quality) data in a continuous fashion based on user defined configurations. Other teams expect the events in a JSON format with no schema enforcement during ingestion and routing time. This makes the platform extremely flexible for producing events and passes on the requirement of knowing the events’ shape to the data consumer. All events go through Kafka internally, making it the backbone of the data platform.
When do we need to deserialize messages as JSON values?
There are several use cases where our Kafka consumers need to deserialize messages as JSON values. These include:
- When forwarding data from an external topic to the Data Platform
- When dispatching data to a destination that expects JSON messages (e.g REST service, Elastic Search, SQS, or another Kafka topic defined to contain JSON data)
- When applying rules and validation on JSON data to measure data quality.
In these cases, we need to configure Kafka consumer deserializers to:
- Map from AVRO to JSON when the topic is AVRO encoded
- String to JSON when the topic is JSON encoded.
Needless to say that asking our users to tell us what their data looks like means they’ll have to add an additional boiler plate to their configuration. But without this, there is more risk of the system being misconfigured and breakages occurring. We would also need to set a few configuration settings, but in practice, we only support a limited number of actual configurations.
The solution — AUTO JSON deserializer
Our first assumption was that there wouldn’t be a bulletproof solution to infer the data format automatically, but we thought that we might be able to reach a good initial approximation.
We started by checking only ‘\0’ vs ‘{‘ as we thought our customers would be only sending JSON objects. Well, no. They also send arrays 🤦♂️. Oh wait, this is working great. Hold on, a few topics are stuck processing specific messages. Oh we see, some JSON nulls are over there.
Regarding the deserializer implementation, we started by applying the detection logic to the first message read. We then expanded this to continuously detect the format on every message (and we produce metrics based on this). This gave us an insight into predicting the system’s behaviour as it wasn’t dependent on the initial state of the topic but it remained consistent across restarts. It also gave us better visibility and debug tools.
After a couple of deployments, and after draining a good set of heterogeneous production topics, we arrived at the following deserializer which is widely used in our platform today:
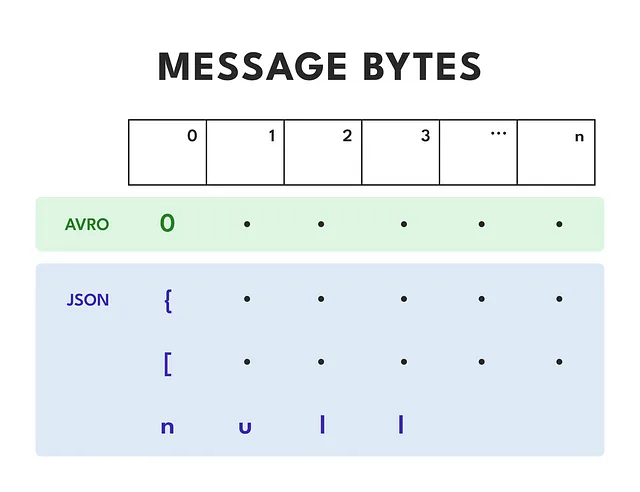
If the message’s first byte is:
- a zero, assume that it is a Confluent Magic Byte and it will be mapped from a Confluent AVRO message to JSON
- ‘[’ or ‘{’, assume that’s a String JSON object
- ’n’ and the whole message is ‘null’, assume that it is a string representing a null JSON object
If the AUTO deserializer cannot infer the type, a deserialization error will be raised (and we’ll look to see the metrics).
Although a more exhaustive validation can be performed (for instance checking that the AVRO schema id is present in the schema registry), we wanted the automatic detection to have a minimal performance impact and to be conservative in order to avoid misinterpreting data. We are open to extending this logic if required, and not just to cover all theoretical inputs.
Pros
- Users don’t need to specify the topic source format
- We were not blocked while migrating components by chasing users
- Users can mix formats within the same topic (deserializer works at event context, although this is highly discouraged!)
- Users can always override it by selecting the proper deserializer
Cons
- Insignificant overhead of calculating which deserializer to apply
- There is no fail fast which means that the production of an incorrect data format may be hidden
- Edge cases like “white spaces” or “numbers”, etc. weren’t considered (If the need arises, we’ll support them)
- The outcome
Two applications use AUTO JSON deserialization:
- Duratro: a legacy application similar to Kafka Connect Sinks. AUTO deserialization is sticky where a deserializer is instantiated as either JSON or AVRO based on the first message read.
- Pipes: Duratro’s evolution, a multi-tenant context platform based on stream fibers. AUTO deserialization context is stateless as it only relies on the message received.
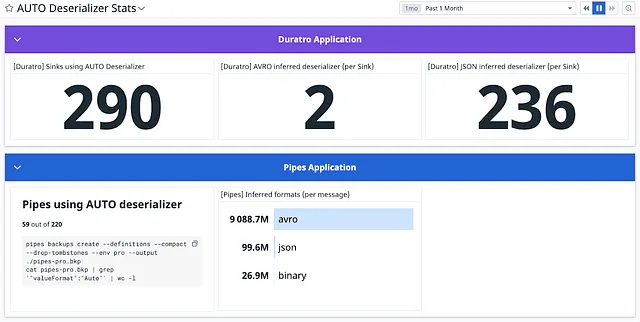
For the last month, Duratro had:
290 Sinks (running integrations) configured to use the AUTO JSON deserializer
- 2 instantiated an AVRO to JSON deserializer
- 236 instantiated a JSON deserializer
- 52 integrations had no traffic
For the last month, Pipes had:
59 Pipes (running integrations) configured to use the AUTO JSON deserializer
- ~9B messages converted from AVRO to JSON
- ~100M messages deserialized with a JSON deserializer
- ~27M messages treated as binary data
To round off, Duratro AUTO deserialization has been running billions of messages for over a year (first commit “committed on 25 Sep 2020”), whilst Pipes has AUTO deserialized 20B messages in the last three months.
Final words
Mastering data formats and their fit in your preferred storage will uncover new possibilities for your data products. In the exposed Kafka example, identifying the gap between AVRO and JSON formats enables you to build your application’s core logic in a format agnostic way, thanks to generic deserializers.
Needless to say that enforcing types is always a good practice: However automation and best effort mappings can be convenient for side cars or migrations. For most cases, a best effort approach driven on data can be more than good enough to achieve your goal.


