

By Alejandro Alvarez Perez and Aleksandar Jovanovic.
Like an organisation, product experimentation can be seen through the lens of process, culture and tooling. Let’s call these an organisation’s cogwheels of innovation. These are the things that, when working well together, multiply the value from each experiment. In this scenario, if you break one cog you’ll hear screechy, grinding sounds in the machinery.
In Adevinta’s Dutch online marketplace, Marktplaats, we posed ourselves two questions: In which of these areas are we excelling? And in which less so? We realised that none of the three areas — process, culture, tooling — could be neglected. We really needed to create agile processes, foster an experimentation culture and mindset, while empowering operations with fit-for-purpose tooling.
We saw a clear starting point, though. Today’s article will take us through the journey of how we matured Fisher, our A/B testing package. In the end, we were able to free up our Data Scientists’ resources, and eventually scale up to a full fledged statistical engine for our global experimentation platform Houston.
The problem
If our Data Scientists were craftsmen, then A/B testing used to be our craft. A/B tests were a gateway to creative exploratory data analysis that we rigorously deployed, aiming to provide our product teams with as much learning as possible. Quite literally, we spent days analysing experiments and crafting insights and reports. Certainly, we were winning, or losing, but we were not doing so very early, nor quickly. The analysis step was long and the Data Scientists were often the bottleneck in the innovation process. Especially, when the number of experiments at any given point was high. All in all, we had a scalability issue, and the main question to be answered was: How can we reduce the time a Data Scientist spends on an experiment?

The solution
The Marktplaats team built Fisher: a python package that enables our Data Scientists to run straightforward hypothesis testing and to produce comprehensive reports with very few lines of code. Fisher supports the entire analysis workflow: from fetching experiment meta(data), to applying standard data cleansing procedures and transformation, to generating the final report. It integrates neatly into our teams’ ways of working by connecting to Jira, Github and different databases, rendering the entire analysis workflow close to fully automated.
Written in the object-oriented programming paradigm, the package has grown to be an ecosystem and vessel for advanced methods that give our experiments some edge. Over time, we’ve implemented variance reduction methods like CUPED, and corrections to multiple-testing scenarios. Respectively bringing down the time-to-learning by cutting the runtime of our experiments substantially and upholding the quality of the inference. Fisher being the common tool, makes introducing such advances smoother across the board. Enabling a new feature for all Data Scientists is done as fast as pull requests can be made.
A sample code chunk of the analysis step with Fisher:
from fisher import Analysis, Report, TTest
data = …
tests = …
analyser = Analysis()
results = analyser(tests=tests, method=TTest(), data=data)
report = Report.from_jira('bnl1234', results=[results])
report.save()The look and feel of the main analysis actions in Fisher. The analysis class orchestrates the hypothesis test with a simple t-test on a dataframe characterised by entity, variant and metrics columns. The Tests class represents hypothesis tests that are characterised by contrasts, dependent variables and segments that map the content/columns of the dataframe, as well as other input parameters for the error-types alpha and beta. Validity assessments and diagnostics are recorded under the hood and can be accessed as part of the analysis metadata. The Report generates a report and renders it as an html page. This is done based on the experiment design fields on the Jira tickets maintained by the experimenting team and the current analysis results.
The Outcomes
We’ve seen the adoption of Fisher ramping up ever since its early days as an internal product. Over 90% of all experiments in Marktplaats were conducted with Fisher within the first year of its introduction. We have seen Data Scientists’ hands-on time go down to an average of 3 hours per experiment. All in all, we estimate freeing over 9 full weeks per year, at the current rate of experimentation. And most importantly, we have achieved our goal of enabling faster experimentation by removing the bottleneck we faced!
So, we sat back and enjoyed our moment of glory..
Or not.
The scale we had just achieved in Marktplaats was great, but Adevinta is a group of online marketplaces across Europe. Other brands are Kleinanzeigen in Germany, leboncoin in France and Subito in Italy. There was a much larger scale to unlock when it came to enabling experimentation through tooling.
Fisher at scale
While the Marktplaats team was developing and using tools like Fisher, one of Adevinta’s central teams developed a relatively mature, marketplace agnostic A/B testing platform called Houston. Houston has already established a robust infrastructure with a comprehensive platform, user interface, and automation capabilities for data storage and tracking, becoming a de facto experimentation tool in many of our marketplaces. And around the time when the Marktplaats team decided to investigate how they could leverage Houston, the Houston team was thinking about how they could extend their analytics capabilities to support state-of-the-art methods at scale.

The two teams realised that they complement each other well, and joining forces seemed like an obvious next step. It didn’t take long before Fisher was adopted into the Houston ecosystem, and became a central analytics toolkit to be shared across all Adevinta marketplaces.
By adopting Fisher, Houston became the central hub for all statistical analysis and experimentation within the Adevinta group. The platform seamlessly incorporates Fisher’s features, creating a powerful combination that elevated the organisation’s data-driven decision-making processes. With it, doors to many new possibilities were opened.
The three biggest improvements were:
- Support for Advanced Analysis Mode within the Houston platform
- A centralised Stats-Engine Service for statistical computations
- Enabling a Unified Experimentation Research process
Advanced Analysis mode
First to come was the advanced analysis option directly within the Houston platform. Leveraging the capabilities of Fisher in Jupyter notebooks, Houston now offers an extensive range of statistical analysis tools, making complex hypothesis testing, data cleaning and report generation more accessible. This allows analysts to perform custom analyses and go beyond what is available in the Houston UI.
Stats Engine for Houston
Our next improvements followed naturally. The need to enhance analytical capabilities independently of the rest of the already complex system of tracking, assignment and Houston UI, gave birth to Adevinta’s experimentation stats-engine — Nightingale. Nightingale, leveraging Fisher, could now become the engine powering all complex statistical calculations in Houston. This helped ensure consistent and reliable results across Adevinta, and enabling new methods in the Houston UI became as simple as calling a different endpoint in the Nightingale service.
Enabling Unified Experimentation Research
Last, but not least, having a central place for implementing analysis methods, and a well defined interface around it, opened the opportunity to propel company-wide experimentation research like never before. With the creation of Experimentation Labs, and leveraging Fisher for implementation of statistical analyses, the Houston team created a simulation and validation toolkit that allows us to seamlessly test new methodologies on synthetic data, modelling many complex processes that could be encountered in reality. As a result, we can quickly make sure that whatever we release provides value even before being applied to real-world use cases.
In addition, every successful research project that yields benefits is then smoothly integrated with Nightingale thanks to both of them using Fisher. This allows every analysis to eventually end up in the Houston UI, enabling everyone in the company to reap the benefits of experimentation research. And thus the circle from research to production is closed seamlessly, enabling continuous improvement and development of the whole platform.
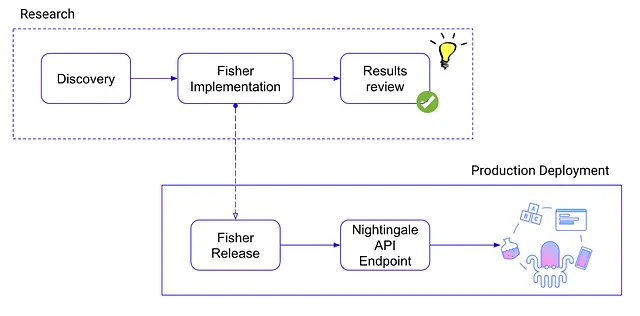
A diagram showing high-level steps in the research process — from idea conception and discovery, to deployment in production.
Conclusion
Fisher is a story of collaboration, teamwork and a shared drive for excellence. It shows how well planted seeds can grow deep roots and become something much bigger — a platform and a community that is significantly more than the sum of its parts. With Fisher as a key component of our experimentation platform and our analytics toolkit, we have made experimentation faster and better, and opened the door to further incremental improvements. We are looking forward to seeing where it takes us in the future!


