

First, a brief summary
The way EKS treats your NodeGroups is very explicit in the AWS API for EKS. The abstractions by CDK and CloudFormation can make this behaviour less obvious, however.
Defining names for your EKS Managed NodeGroups invites errors into your deployments that can be painful to manage as workloads grow.
This article’s purpose is not to criticise the design choices of these tools but to provide a cautionary tale for other engineers working with these components.
So what’s the story?
At Adevinta we faced an incident recently. We were trying to have more descriptive NodeGroup names to make them easier to identify, so we decided to rename them. No big deal, right?
WRONG.
We wanted to rename the NodeGroups for our EKS clusters to have more visibility of which NodeGroup belongs to which cluster when processing NodeGroup metrics in Grafana. The end goal was to improve our alerting system.
We evaluated the situation and agreed that renaming the NodeGroups was the easiest way to achieve this goal.
Soon after rolling out the change, we found out we had miscalculated the impact of this seemingly insignificant change.

These notifications will wake you up faster than any cup of coffee ever will.
All the NodeGroups were replaced aggressively. It took 8 WHOLE MINUTES for one of the most critical clusters to run all its pods again. Approximately 40 nodes per NodeGroup wiped in about a minute.
Unknown to us at that time, this is expected AWS behaviour.
If we check the API for the UpdateNodeGroupConfig struct in the AWS SDK for Golang we see that we can update many properties of the NodeGroup — but not the name. That means that renaming requires calling the CreateNodeGroup method and then the DeleteNodeGroup method. Which is what AWS does.
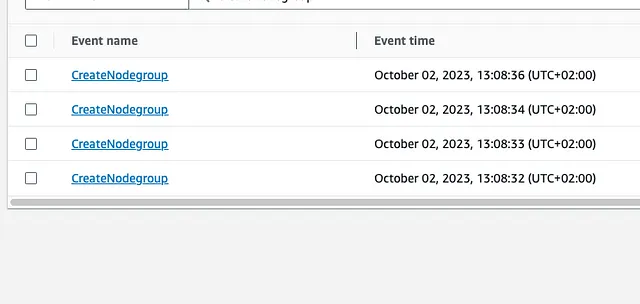
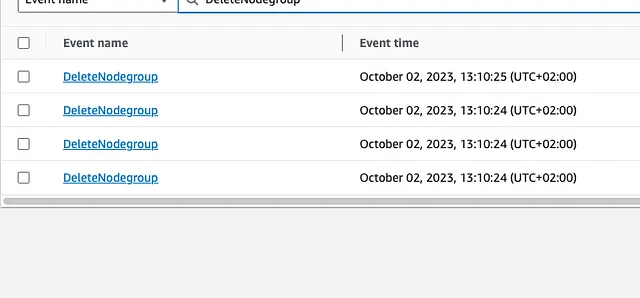
You can see that the deletion calls were made around two minutes after the creation calls. This is not enough time for the nodes to warm up and pods to move around. You can see below in that little roller coaster ride how aggressively our Ready nodes went down and then up.
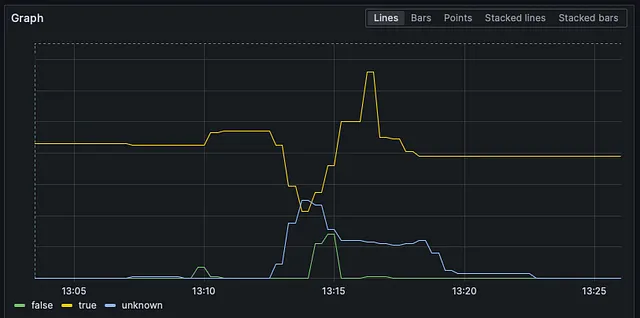
But wait… If the API doesn’t allow us to do this, how did we fall for it anyway?
Enter AWS CDK…
CDK offers many utilities to manage AWS infrastructure in a more convenient way. Often these are direct translations of CloudFormation functionalities.
If we take a look at the docs for the AWS::EKS::Nodegroup class in CloudFormation, we can see that renaming any NodeGroup requires a replacement.
NodegroupName
The unique name to give your node group.
Required: No
Type: String
Update requires: Replacement
This means that the NodeGroup will be replaced when the update call is made. That is, AWS will create a new NodeGroup with the new name and then destroy the previous one.
If we look at the CDK docs, it says that the name of the NodeGroup is autogenerated if not provided but there’s no comment about the NodeGroup being replaced if the name changes. Unless you double-check with the CloudFormation docs, this is easy to miss. And miss it we did.
But wait, there’s more!
We cannot have static names for NodeGroups anyway. Defining the group name can lead to failed updates in your CloudFormation stacks. Remember how I mentioned that AWS will create the new NodeGroup and then delete the previous one? Combine that with the fact that EKS NodeGroup names are unique and you get a CreateNodeGroup API call that cannot succeed because the name is already in use.
Resource handler returned message: “NodeGroup already exists with name NPD
and cluster name n64b77dd (Service: Eks, Status Code: 409, Request ID:
b5a0bb92-b470-d3dac4296c14)” (RequestToken: 12dfe42e-addc-
091fa86fb01e, HandlerErrorCode: AlreadyExists)
This would only occur if you try to make any change that will create a NodeGroup replacement, like the AmiType or DiskSize without changing the name of the NodeGroup. This is a pretty likely scenario.
So what’s the best practice here?
Don’t name your NodeGroups if you’re using CDK. Let CDK name them for you. As the property NodeGroupName of the NodeGroupOptions struct in CDK describes, the name will be automatically generated if not provided. This name includes a hash that doesn’t change if the configuration for your NodeGroup doesn’t change. As a bonus, it will use the ID provided in the AddNodeGroupCapacity call as part of the random name.
Add PDBs to critical components. We noticed that our cluster’s critical components were not as badly impacted by the replacement as users’ applications that did not have them.
Another thing to be aware of is that these gotchas are unpredictable. You cannot be aware of all the limitations of all the tools that you’re using. Running into edge cases is the bread and butter of DevOps, that’s why you need other procedures and tools to watch for unusual behaviour in daily operations.
We have not come to a conclusion yet but our monitoring system will definitely be improved after this incident. We have data we can aggregate and fine-tune with time.

Closing remarks
Don’t name your EKS NodeGroups if you’re using CDK. Or consider not having NodeGroups at all…
Cloud is hard. It’s a tough challenge for any Cloud Provider to produce functionalities that cover all the use cases for all of their users. So I’m not going to blame the provider.
It’s hard for DevOps/SRE teams to detect all of these issues. In these cases being present and accountable to your users is the best approach.

And of course, take your learnings and add to your backlog any improvement for monitoring or code management that will work as guardrails for the future.
Until the next incident!


