

Correlation or causation?
“Correlation does not imply causation.” Is this phrase familiar to you? It’s often used to critically question the assumptions about cause and effect relationship based solely on the coincidence between two events. In this blog, I explain how we use causal inference at Adevinta to reveal why customers are making certain decisions and predict the actions we should take to influence those decisions.

A lot of us are excited when two events happen at once, and say that one must be because the other happened. Some explanations claim that the human mind is wired to look for patterns and causal relationships, even when they do not exist. This is especially true when the coincidence occurs repeatedly, reinforcing the perceived relationship. Simply, we don’t conclude that A causes B from only one observation, but if event B frequently coincides with A, we likely assume that A causes B. That’s “good old common sense,” which is not fully accurate.
One of the main differences between correlation and causation is temporal precedence. This means X is a cause of Y only if X occurs before Y. Therefore, causality is asymmetric, which means “X causes Y” does not imply “Y causes X”. In contrast, correlation is symmetric between two variables: “X is correlated with Y” is equivalent to “Y is correlated with X”.
Let’s look at the graph below:
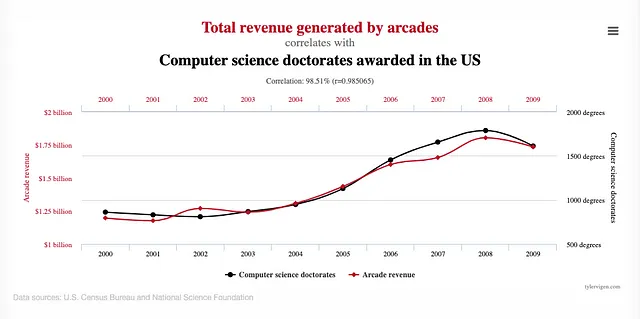
Is that coincidence? Or does this mean that more people going to arcades really causes more people to be awarded computer science doctorates? Does this mean the US should invest in more arcades in order to ensure there are more computer science graduates? The graph shows why it is crucial to distinguish between correlation and causation. Making assumptions about causation based on correlation can lead to incorrect conclusions and even harmful actions.
What is causal inference and why is it important?
In simple words, causal inference is the process of estimating how changes in one input can affect the other variables. This allows us to make a proper intervention about the future based on what happened in the past. By understanding why a customer is making certain decisions, such as churning or repurchasing, their reason for doing so will seriously impact the success of our intervention.
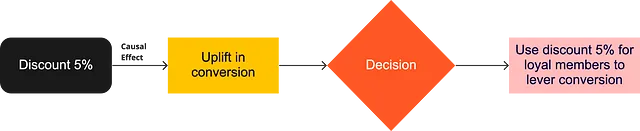
So, what is the difference between causal inference and prediction:
- In prediction: What’s the next Y, given X?
- In causal inference: What happens to Y if X is changed?
Causal inference aims to answer the following questions:
- Did a marketing campaign lead to a higher Click-through Rate (CTR) across our websites?
- When we release a new feature for a product, does this increase the customer engagement?
- What will be the impact of investing in X?
Take the example of churn prediction which aims to understand which kind of successful intervention to use to keep a user loyal: the insights are often unusable if the cause couldn’t be analysed and understood. An A/B test might help us estimate the impact of product changes (like if a new feature is likely to increase churn) on KPIs like CTR, but hardly tells us why a customer is likely to churn. Also, it’s not really possible to run an infinite number of A/B tests to identify the causes of churn. There are many important causal questions that A/B tests couldn’t fully answer.
Confounding Variables (Confounders)
Now let’s imagine we would like to test whether eating candy makes you happy. What if we found out that our friends who eat candy are also the ones who have more free time, while the friends who do not eat candy have more stress with housework? In that case, it might not be the candy that’s making people happy — it could be the extra free time!
This “free time” variable is called a confounder — the factor which can affect both the thing we investigate (candy) and the output to be observed (happiness). Confounders are also the events that can cause both A and B, making A appear to cause B. When confounders exist, it could be hard to tell if the thing we’re investigating is really causing the outcome we’re interested in, or if confounders are actually the cause.
Back to our example. To really know if candy makes people happy, we need to take into account the amount of free time each person has, so that we can see if there is still a connection between candy and happiness once we remove the effect of the confounder.
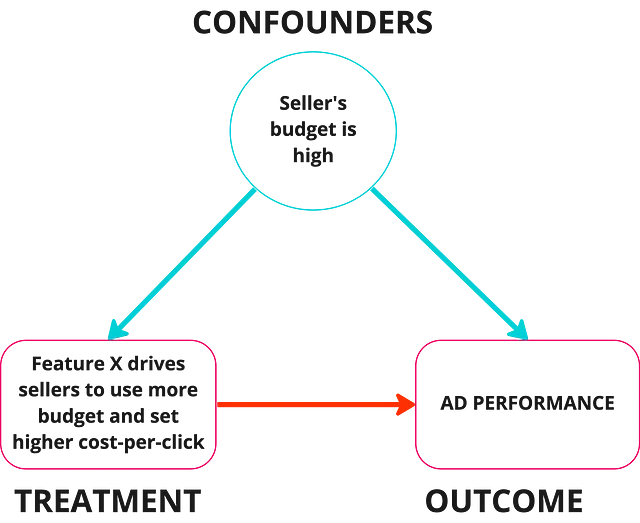
In the context of classifieds ads with the cost-per-click (CPC) model, possible confounders are those factors that influence both ad performance Click-through-rate (CTR) and its Cost-per-click (CPC).
For example:
Causal questions: The effect of new feature X, released last week, on ad performance of sellers
Challenges: Pre-treatment differences exist as ad performance can also depend on multiple factors, including:
- Ad Content: The content of an ad can greatly affect its performance. Ads with more attractive headlines, images and descriptions or in a “hot” category may get more clicks, regardless of the CPC.
- Ad Position: Ads placed on top of the website in page 1 might get more clicks due to greater visibility, regardless of the CPC.
- User Demographics: User demographics, such as age, gender and location could affect ad performance. Certain ads may be more appealing to specific demographics, leading to differences in CTR.
- Time of Day/Week: Ads may perform differently depending on the time of day or week they are displayed. For example, ads shown during peak browsing times (like before Christmas) may get more clicks, regardless of the CPC.
- Competition: The level of competition in a given ad category could affect the CPC and ad performance. Ads with higher CPCs may be placed in more competitive categories, leading to differences in CTRs.
- Ad Historical Performance: An ad’s past performance may affect its current performance. Ads that have historically performed well may successfully promote the seller’s brand to buyers and are likely to continue to perform well, regardless of the CPC.
- Seller’s Budget: If a seller with a lower budget sets a lower CPC, their ad may be displayed less frequently or in less prominent positions, leading to lower CTR even if the ad itself is well-designed and relevant to users.
Randomised control trials
So, how can we minimise the effects of confounders? By randomly assigning participants to either the treatment or the control group, aka randomised control trials (RCT).
For example, let’s say FIFA tries to figure out if a new kind of ball helps players score more goals before the World Cup. FIFA would randomly pick some teams to play with the new ball, and some teams to play with the standard ball. With this randomness, FIFA would not have any special reason to pick one team over another. Every team has a fair chance to play with either ball.
Then FIFA would watch and see if the teams playing with the new ball score more goals than the teams playing with the regular ball. If they do, then it could be said that the new ball really helps players score more goals!
By randomly assigning teams to either the treatment group (play with new ball) or the control group (play with standard ball), a randomised control trial ensures that any confounders are distributed equally across both groups. This makes it more likely that any differences in outcomes between the two groups are actually due to the treatment being tested, rather than to other factors.
The general principle of randomised control trials can be implied: assuming the constant from all other factors, the difference in outcome can be completely attributed to the difference in treatment.
The randomisation process helps to minimise the effects of those confounders and make the results more reliable. It still, however, should be noted that there may still be some confounding variables that are not fully controlled for, even in a randomised control trial.
Another issue of random sampling is it’s possible to introduce bias in the process of selecting the sample groups. For instance, random sampling in “DIY Category” is much different from random sampling in “Car Category.” There are many ways that bias can be generated from the sampling process. Essentially, a good sample is representative of the population of interest.
Furthermore, it’s always recommended to check for balance between the treatment and control groups. This means, for example, we would like the treatment and control groups to have roughly the same average ad performance, with respect to known confounding factors.
This can be done by comparing the means or distributions of relevant variables in the two groups. The point is to ensure that any observed differences in outcomes can be attributed to the treatment being tested rather than differences in the characteristics of the groups. If the groups are not balanced, it may be necessary to adjust for these imbalances in the analysis or to re-randomise the study participants.
In general, we have to be very careful in data gathering.
Statistical significance or business significance?
To evaluate whether the treatment (whether the new feature improves ad performance/ CTR) has an effect, we compare the average CTR between the treatment and control groups (aka group means). These averages and groups are comparable thanks to the law of large numbers, which states that the more the sample sizes are increased, the closer the average of the sample will be to the population average.
Even when we draw samples from the same population, there will always be some variation between the means of different moments of drawing. This variation occurs by chance and is an inherent part of the sampling process, or sampling error. Hence, the question we need to answer is whether the observed difference between the group means is real or simply due to chance. This is where statistical significance comes into play.
But how? This is the p-value technique in hypothesis testing. The p-value tells us the probability of getting the difference between group means if there was actually no difference between the groups. When the p-value is very small (e.g. p < 0.05), it indicates that the difference is unlikely to be by chance, and we call this result statistically significant.
It should be noted that although we evaluate the average values or means of two groups, the statistically significant result also depends on the standard error or the uncertainty of the means.

Another factor that can affect the significant result is the sample size. If we increase the sample size, the variability of the results will decrease, resulting in a smaller p-value. Therefore, when we design an experiment, it is important to consider the sample size required to achieve a statistically significant result. Power of a test is used to identify the minimum sample size necessary to get a statistically significant result.
It’s important to remember that statistical significance is not always equivalent to business value. Business significance refers to the practical importance in a broader KPI context such as cost of change, return on investment or budget for business decisions.
For example, a statistically significant increase in sales of 0.1% may not have any practical significance for a large company, while a statistically insignificant increase in sales of 5% may be highly significant for a small business. Therefore, both statistical significance and business significance must be taken into account when making decisions based on data analysis.
Simple causal model in a classified advertising context
Let’s return to our question:
Causal questions: What’s the effect of new feature X, released last week for some sellers, on ad performance?
The new feature X aims to stimulate sellers to use their budgets more efficiently. Let’s say we split our sellers into treatment (those introduced new feature X) and control (those who didn’t experience new feature X), and our question will evaluate whether the new feature really has a positive impact on ad performance — CTR. If yes, the final decision is to fully roll out this new feature for all sellers.
If the following (big) assumptions are met:
- Linearity: The relationship between the dependent variable (Ad CTR) and the independent variables (Seller Budget, Ad CPC, Ad Position, Ad Impression and Treatment) is assumed to be linear. “Naively” speaking, higher seller budget leads to higher ad CPC, and hence higher Ad position.
- No multicollinearity: The independent variables are assumed to be not highly correlated with each other.
- Causal ordering: The causal diagram represents the correct causal ordering of the variables, following the business model.
- No unmeasured confounding: There are no unmeasured confounders which can impact on both the independent and dependent variables.
Then we can draw the causal graph as follows:
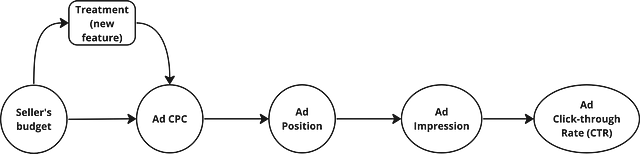
The model, mathematically, can be represented as:
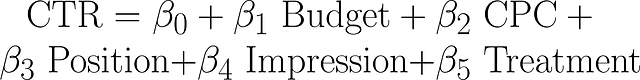
where:
- β1 is the effect of Seller Budget on Ad CPC
- β2 is the effect of Ad CPC on Ad Position
- β3 is the effect of Ad Position on Ad Impression
- β4 is the effect of Ad Impression on Ad CTR
- β5 is the effect of Treatment on Ad CPC
- Treatment is a binary number. Treatment is 0 for sellers from the control group, while treatment is 1 for sellers who experienced feature X (treatment group). So, the new feature X indirectly affects Ad CTR through the effect of increased seller’s budget on Ad CPC.
It’s noted there are also some technical assumptions of the model error in this linear approach, including:
- Independence: The errors of linear models are assumed to be independent of the independent variables.
- Homoscedasticity: The variance of the model errors is assumed to be constant across all levels of the independent variables.
- Normality: The errors are assumed to be normally distributed.
With this simple approach, we can evaluate the treatment effect (new feature X) by comparing the regression coefficients of Treatment, β5, and the other predictors. If the coefficient of Treatment, β5, is significantly greater from zero (one-tailed test), it suggests that the new feature X has an effect on Ad CTR, after controlling for other variables. Again, it’s also worth confirming whether statistically significant results bring any business or practical significant output.
Takeaways
Correlation is always a good starting point for business. Correlation means there could be an indirect link between two events, however, we need to understand the difference between correlation and causation. Correlation can help businesses predict what will happen, but finding the root cause of something means you can intervene.
We sense the causality by analysing correlation, then running experiments where we control the other variables and measure the difference. A moderate level of correlation is good, and a degree of causality can be valuable and critical in making data-driven decisions. It’s essential to identify and account for confounders to ensure accurate causal inferences.


